IBM Data Replication (CDC)
If data retrieval from source systems is a problem for the data warehouse
IBM InfoSphere Data Replication is a database replication solution offered by IBM that propagates changes on the source database side to the target database by reading database logs.
By monitoring the logs, changes are reflected in the target database near real-time.
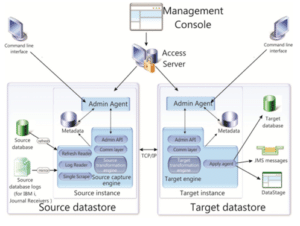
According to the Data Replication architecture diagram below (source: https://www.ibm.com/docs/de/idr/11.4.0?topic=replication-administering-management-console),
the Access Server element is responsible for operating the replication. It is recommended to deploy the Access Server on a standalone infrastructure element and, after setting up the mandatory firewall rules, connect to the servers hosting the source and target databases. It is necessary to install the Admin Agent (the element that manages replication on the server, more commonly known as Replication Engine) on every the database servers.
The source Engine reads the database logs, transmits the database changes to the Access Server, which forwards them to the Engine installed on the target database. The Engine on the target side implements the insert, update, delete operations in the target database that occurred on the source side.
Databases affected in the operation do not own a dedicated direction, so each installed Engine is capable of capture data (“copying” its changes) as a source, as well as a target database, if the firewall and network rules provide this.
A graphical interface called Management Console supports the hands-on replication configuration. The Management Console can be installed on the same server component where the Access Server is available, or even on a standalone infrastructure element – after mandatory security configuration.
Using the Management Console interface, one can perform the following tasks:
- User management: Manage the system users and their security level
- Database configuration: Add databases with Replication Engine to the list of databases available for replication on the system
- Manage replication: Specify the replication subscription rules between the tables of the databases configured in the previous section
Two methods of replication:
- Mirroring: Replication between the tables configured on the source and target side is operating continuously from the moment the process is started until it is stopped. This means that changes made on the source side are reflected in the target database in near real-time. As replication first started, a complete source snapshot is loaded into the empty target database tables, after this initial load the system switches to the mirroring-based method.
- Snapshot load: During snapshot load, the data movement between source and target is not continuous, but one-off. The database state at the time the load is initiated is replicated into the target database, once this is complete, any further change on the source side is not reflected on the target side until the user initiates another load. In case of a full snapshot load, the entire source side is replicated to the target side, regardless of the previous state, in contrast of a delta load, when only the changes that have occurred since the previous snapshot load are replicated to the target database.
IBM InfoSphere Data Replication bear the ability to move data between a wide variety of database types, but the design of the process requires the appropriate configuration of each column type to allow compatibility between two different types of databases.
For the tables involved in the replication, it is mandatory that any modification made on the source side will be implemented on the target side in order to maintain synchronous operation between the two sides.
Replication helps initiate appropriate backup systems, offload live databases and allows additional analytical systems to be built on top of replicated databases. The resources of a replicated database are ideal for serving daily operational processes such as data reporting or further data transformation, ensuring the integrity of the raw data on the source side.
RELATED INDUSTRIES


Banking and financial sector
Barré solutions for banks, insurance companies, credit guarantee insurers
