IBM Data Replication (CDC)
Ha gondot jelent az adatkinyerés az adattárház számára forrásrendszerekből
Az IBM InfoSphere Data Replication az IBM által kínált adatbázis replikációs megoldás, mely a forrás adatbázis oldali változásokat a logokból kiolvasva közvetíti a cél adatbázis felé.
A logokat monitorozva a változások közel valós időben jelennek meg a cél adatbázisban.
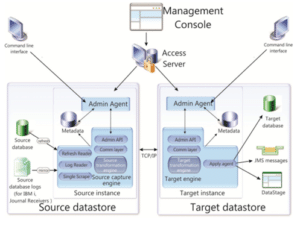
Ahogy a következőkben látható Data Replication architektúra ábrát tanulmányozva látszik (forrás: https://www.ibm.com/docs/de/idr/11.4.0?topic=replication-administering-management-console),
az Access Server felel a replikáció vezérléséért. Az Access Servert ajánlott egy önálló infrastruktúra elemre telepíteni, és a megfelelő tűzfalszabályok beállítása után kapcsolatot kialakítani a forrás és cél adatbázisokat üzemeltető szerverekkel. Utóbbiakra szükséges telepíteni az Admin Agent-et (az adott szerveren a replikációt felügyelő elem, hétköznapibb megnevezése Replication Engine).
Az Engine olvassa az adatbázis logokat, közvetíti az adatbázis változásokat az Access Server felé, mely azt továbbítja a céloldali adatbázishoz telepített Engine részére. A céloldali Engine ennek alapján implementálja a cél adatbázisban a forrásoldalon bekövetkezett insert, update, delete műveleteket.
Az egyes adatbázisok nem rendelkeznek dedikált iránnyal, azaz minden telepített Engine mind forrás-, mind céladatbázis kiszolgálásra (változásainak “másolására”) alkalmassá válik, amennyiben a tűzfal-, és lokális szabályok is biztosítják ezt.
A felhasználói oldalról egy Management Console-nak nevezett grafikus felület támogatja a replikációs beállítások elvégzését. A Management Console telepíthető ugyanarra a szerver elemre, ahol az Access Server is elérhető, de akár önálló infrastruktúra elemre is – természetesen megfelelő biztonsági beállítások után.
A Management Console felületen az alábbi feladatokat lehet végrehajtani:
- Felhasználókezelés: A rendszer felhasználóinak és jogosultsági szintjének beállítása
- Adatbázisok beállítása: Replication Engine-nel rendelkező adatbázisok hozzáadása a rendszer replikációra elérhető adatbázisainak listájához
- Replikációs szálak konfigurációja: A megelőző pontban beállított adatbázisok táblái közötti replikációs szabályok megadása
A replikációnak alapvetően kétféle módszertana létezik a rendszerben:
- Mirroring: A forrás- és céloldalon beállított táblák között a replikáció annak elindításától folyamatosan történik, egészen annak leállításáig. Ezáltal a forrás oldalon megtörtént változások közel valós időben megjelennek a céloldali adatbázisban is. A replikáció első elindításakor az üres céltábla töltéséhez egy teljes forrás másolat (snapshot) kerül be a céloldali adatbázisba, majd ennek megvalósulása után vált a rendszer a tükrözés alapú metódusra.
- Snapshot töltés: Snapshot töltés során az adatmozgatás nem folyamatos a forrás- és céloldal között, hanem egyszeri. A töltés indítása idején érvényes állapot kerül átmásolásra a céloldalra, amint ez befejeződik, a forrás oldalon bekövetkező további változások nem jelennek meg a céloldalon, egész addig, amíg nem indít a felhasználó egy újabb töltést. A teljes snapshot töltés esetén a teljes forrásoldal újramásolásra kerül a céloldalra, függetlenül attól, hogy ott mi volt a korábbi állapot, míg a delta töltés esetén csak a megelőző snapshot töltés óta bekövetkezett változások kerülnek át a céloldalra.
Az IBM InfoSphere Data Replication lehetővé teszi a legkülönfélébb adatbázistípusok közötti adatmozgatás lehetőségét, de a folyamat kialakítása megköveteli az egyes oszloptípusok megfelelő beállítását, mely kompatibilitást tesz lehetővé a két különböző típusú adatbázis között.
A replikációban érintett táblák esetében elvárás, hogy bármilyen, a forrás oldalon elkövetett módosítás megvalósításra kerüljön céloldalon is, hogy a két adatbázis közötti szinkron működés megmaradhasson.
A replikáció segíti megfelelő backup rendszerek kialakítását, tehermentesítheti az éles adatbázisokat, és lehetővé teszi, hogy további analitikus rendszerek épüljenek a replikált adatbázisokra. A replikált adatbázis erőforrásai ideálisak az operatív működés kiszolgálására, úgymint adatszolgáltatás vagy további adattranszformáció, ezzel is biztosítva azt, hogy a nyers adatok integritása változatlanul megmaradjon forrásoldalon.